In december 2023 gaf Mike Wooldridge op het Royal Institution een reeks laagdrempelige college’s (1) over vraagstukken rond AI. Woolridge is hoogleraar informatica aan de Universiteit van Oxford. Hij is zo’n typische Britse professor met een groot en aanstekelijk enthousiasme voor het thema dat hij behandelt. In college‘s van ruim een uur zet hij een goed te begrijpen samenvatting neer van wat AI is en waar AI ons zal brengen.
Centrale vraag:
AI kan nu mensachtige taal en kunst creëren – maar welke andere deuren kan het in de toekomst openen? En hoe kunnen we AI benutten om grote sprongen in technologie mogelijk te maken?
Aangevuld door kennis uit andere bronnen, probeer ik in deze postings een samenvattend verhaal te schetsen op basis van het college van Wooldridge. De begrippen die in de college’s voorkomen heb ik hier en daar middels een verdiepingsbutton (zie het rood omlijnde kader met rechts het plusje) in de tekst met behulp van chatGPT en mijn eigen kleine hersentjes toegelicht. Dit begint natuurlijk al met de termen AI, Machine learning en LLM.
Grote hoeveelheid tekst:
Een LLM wordt getraind met een enorme hoeveelheid tekst, zoals boeken, artikelen, websites en meer. Hierdoor leert het de patronen en structuren van taal in de wereld.
Woorden en zinnen begrijpen:
Het model leert de betekenis van woorden en hoe ze in zinnen worden gebruikt. Het kan bijvoorbeeld begrijpen dat het woord “hond” een dier beschrijft dat blaft en vaak als huisdier wordt gehouden.
Voorspellen en genereren:
Een LLM kan woorden voorspellen en zinnen genereren die logisch en coherent zijn. Als je bijvoorbeeld begint met “Het was een zonnige dag,” kan het model vervolgen met “en de vogels floten vrolijk.”
Antwoorden en conversaties:
Je kunt een LLM vragen stellen of een gesprek voeren, en het zal proberen om nuttige en relevante antwoorden te geven op basis van wat het heeft geleerd.
Aanpassingsvermogen: Het model kan in verschillende contexten worden gebruikt, van het schrijven van essays en verhalen tot het beantwoorden van vragen en het helpen bij het programmeren.
Voortdurend leren: Hoewel een LLM veel heeft geleerd tijdens zijn training, kan het ook blijven leren en verbeteren naarmate het meer interacties en gegevens ontvangt.
Inhoud webpagina:
- Wat is ‘Kunstmatige Intelligentie?’
- Wat is ‘Machine learning’
- Hoe werken ‘neurale netwerken’
- De geboorte van de ‘Transformer’-architectuur in 2017
- Hoe werd GPT-3 gecreëerd en getraind?
- Een enorme stap voorwaarts in AI
- Hoe GPT-3 slaagde voor de 90s AI-redeneertest
- Hoe heeft AI dingen geleerd die het niet geleerd heeft?
- Waarom hebben LLM’s het zo vaak mis?
- De problemen van vertekening en toxiciteit
- Auteursrechtelijke problemen met LLM’s
- Wat maakt menselijke intelligentie uniek en bijzonder?
- Wanneer zal algemene AI (AGI) geïntroduceerd worden?
- De verschillende varianten van Algemene AI
- Is AGI al bereikt?
- Is machine-bewustzijn mogelijk?
- Bronnen:
Wat is ‘Kunstmatige Intelligentie?’
Meteen al met de uitleg van het begrip AI hebben we een probleem: de term verwijst naar ‘intelligentie’ van het menselijk brein maar we weten niet precies wat ‘intelligent’ is. Zeer algemeen gesproken wat betreft dieren en mensen kun je intelligentie definiëren als het vermogen om een situatie te interpreteren, te leren en die kennis en inzicht te gebruiken om zich aan te passen aan nieuwe situaties. Maar bijv de mens is ook in staat om in abstracties te denken, ideeën en taal te begrijpen en te produceren.
Kunstmatig kun je al deze vermogens nabouwen met een machine die je niet alleen taken in een bepaalde volgorde kan laten uitvoeren maar ook tot zelfstandig denkwerk kan programmeren dat zich kan meten met menselijke breinactiviteit. Aan het eind van de 20e eeuw zien we bijvoorbeeld de computer DeepBlue winnen met schaken van grootmeester Kasparov. Er is dan sprake van een analytische machine die gelijkwaardig is aan het menselijk brein of hem zelfs kan overtreffen op cognitie. Niet alleen wat betreft leervermogen maar ook wat betreft het vermogen om inzichten zelfstandig te combineren tot nieuwe kennis.
Toch heeft de mens nog steeds een superieure positie ten opzichte van deze machines. Want mensen hebben niet alleen analytische intelligentie maar beschikken ook over praktische, emotionele, sociale en creatieve intelligentie.
Wanneer AI ook elementen bevat van emotionele intelligentie, begrip , empathie en menselijke emoties waarmee de machine rekening houdt in zijn beslissingsproces dan is er sprake van AGI: Artificial general intelligence.
Wat is ‘Machine learning’
Kunstmatige intelligentie begint belangrijk te worden in de jaren ’50 met de ontwikkeling van de eerste computers die instructies kunnen uitvoeren in een bepaalde gewenste volgorde op basis van een computerprogramma. Maar is dit intelligent? Nog lang niet. In die zin heeft in de 20e eeuw AI zich heel langzaam ontwikkeld. Pas in 2005 komt AI in een stroomversnellling toen ‘machine learning’ op een grote schaal mogelijk werd door het beschikbaar komen van heel veel trainingsdata op het web en verbeterde rekenkracht van nieuwe chips.
Neem de techniek van gezichtsherkenning. Hoe leer je een machine een gezicht herkennen? Je laat hem een foto van een gezicht zien (input) en de computer geeft een antwoord terug (output). Dit kan door supervised learning. Dus door middel van trainingdata de machine gaan leren. De input is dan een set van foto’s van mijn gezicht (de computer herkent patronen in afstand tussen ogen en andere kenmerken) en labelled dan deze verzameling kenmerken met ‘dit is Marlin Burkunk’. Het is dan supervised in de zin van dat we de computer helpen door een foto te geven met een omschrijving. Dit is een classificatie test. De machine classificeert de foto in een bepaalde categorie. Dit classificeren kreeg een hoge vlucht in 2005 en helemaal in 2015 : de techniek maakt het mogelijk om een TESLA te leren ‘dit is een stopbord, dit is voetganger’ etc.
Hoe herkent een neuraal netwerk van een machine nu een gezicht?
Hoe werken ‘neurale netwerken’
Wanneer je naar de inhoud van een brein kijkt dan zie je neuronen. Dat zijn de bouwstenen van de hersenen. Je hersenen bevatten ongeveer 86 miljard zenuwcellen. Dat is twaalf keer zoveel als er mensen op aarde rondlopen! Zo’n cel bestaat uit een cellichaam met een celkern en meerdere uitlopende sprieten. De korte uitlopers heten dendrieten, de lange uitloper heet een axon. Via deze uitlopers kunnen de zenuwcellen in de hersenen met elkaar communiceren. Dat doen ze door elektrische seintjes naar elkaar te sturen. Aan het uiteinde van een axon zit een synaps. Dit is de plek waar twee zenuwcellen met elkaar communiceren. De synaps brengt het signaal via signaalstoffen (neurotransmitters) van het axon van de ene zenuwcel over naar de dendriet van de andere zenuwcel.
Al deze cellen staan in contact met elkaar door middel van gigantische netwerken.
Elke neuron heeft een simpele patroon herkenningstaak. Als hij iets herkent stuurt hij een signaal naar een ander netwerk. Neem de foto van Marlin Burkunk. Die bestaat uit 300 dots per inch. In totaal miljoenen gekleurde pixels die allemaal een bepaalde positie en waarde hebben in het grid. Simpel gezegd slaan neuronen patronen in dit beeld met label Marlin Burkunk op. Als zij een ander beeld voorgeschoteld krijgen met dezelfde patronen dan herkennen zij dit als ‘Marlin Burkunk’.
We begrijpen de werking van dit neurale netwerk niet in detail maar in de jaren ’40 waren er onderzoekers die in het brein wel overeenkomsten zagen met elektrische schakelingen. Kun je dus een brein nabouwen als een machine met schakelingen? In de hele 20e eeuw heeft men hier naar gezocht maar het ging heel langzaam.
Begin 21 eeuw ging alles in een stoomversnelling: drie reden waarom men wel een neuraal netwerk (vergelijkbaar met het menselijk brein) kunstmatig kon nabouwen: 1. er was een wetenschappelijk behoefte wat betreft deep learning en patroon herkenning (medische beeldvorming; zelfrijdende auto’s etc) 2. er waren heel veel datasets waarmee je een neuraal netwerk kon trainen 3. om te trainen en uiteindelijk een voorspelling te berekenen heb je heel veel computerkracht nodig. Die rekenkracht werd pas in 21 eeuw dmv nieuwe chips heel groot en goedkoop (NVIDIA is wereldwijd de grootste producent van deze chips).
In 2005 was de techniek in staat om gezichten te herkennen maar ook patronen van tumoren te herkennen op röntgenfoto’s en MRI’s . In 2012 kreeg de ontwikkeling een nieuw boost door de introductie van de GPU (graphic processing unit) die veel meer berekeningen konden doen in nog minder tijd. De Big Tech bedrijven in Silicon Valley ruiken geld en er worden enorme kapitalen geïnvesteerd om de AI-technologie sterker te maken door meer computerkracht te genereren en meer trainingsdata te verzamelen.
De geboorte van de ‘Transformer’-architectuur in 2017
In 2017 publiceren een aantal onderzoekers die werkten voor Google Brain het artikel ‘Attention is all you need’. (2) waarin een Transfomer-architectuur wordt voorgesteld om een neuraal netwerk in combinatie met een taalmodel efficiënter en effectiever te laten werken. Het artikel betekent een revolutie in de geschiedenis van AI. Het vormt de basis voor de inrichting van GPT: een Generic Pretrained Transformer.
Centraal in deze nieuwe architectuur staat het ‘attentie mechanisme’. Dit mechanisme is zo belangrijk omdat het een efficiëntere en effectievere manier biedt om met sequentiële data, zoals tekst, om te gaan in vergelijking met eerdere minder efficiënte methoden binnen neurale netwerken.
Het attentiemechanisme waarover de onderzoekers van Google Brain publiceren is tot het volgende in staat;
Contextbegrip:
Attentie stelt het model in staat om relaties en afhankelijkheden tussen woorden in een zin te herkennen, ongeacht hun positie. Dit betekent dat het model de context van elk woord in een zin beter begrijpt, wat leidt tot nauwkeurigere interpretaties en reacties.
Parallelle Verwerking: transformers kunnen de gehele input in één keer verwerken. Dit maakt het mogelijk om data parallel te verwerken, wat resulteert in aanzienlijke snelheidswinsten en efficiëntie in training en afleiden van conclusies.
Flexibiliteit en Generalisatie:
Het attentie-mechanisme is zeer flexibel en kan worden toegepast op verschillende soorten taken, zoals vertalen, samenvatten, het beantwoorden van vragen. Het kan ook eenvoudig worden aangepast en geschaald, wat heeft geleid tot de ontwikkeling van steeds grotere en krachtigere modellen.
Minder Vooroordelen in Sequentiële Data:
Omdat elk deel van de input (bijvoorbeeld elk woord in een zin) direct met elk ander deel kan interacteren, vermindert dit het probleem van ‘vergeten’. Hierdoor kan het model lange-afstandsafhankelijkheden in tekst beter begrijpen.
Het attentie-mechanisme heeft de manier waarop machines tekst begrijpen en verwerken fundamenteel veranderd, wat leidde tot aanzienlijke verbeteringen in natuurlijke taalverwerking en aanverwante gebieden.
Een computer kan niet rekenen met tekst. Alleen met getallen. Als we algoritmes willen loslaten op tekstdata dan zullen we deze tekst eerst moeten ‘vertalen’ naar getallen. Met andere woorden: een numerieke representatie vinden.
Dit begon met de introductie van word2vec in 2013: een soort woordenboek waarmee je een woord kunt vertalen naar een reeks getallen met een semantische lading (word embeddings). De innovatie is vooral dat niet alleen door middel van vectoren een woord een getalrepresentatie krijgt maar dat ook de relatie van het ene woord ten opzichte van het andere (context) een getalrepresentatie krijgt. Er ontstaat dus een nieuwe representatie voor woorden waarbij de betekenis min of meer in de getallen ge-encodeerd is.(3)
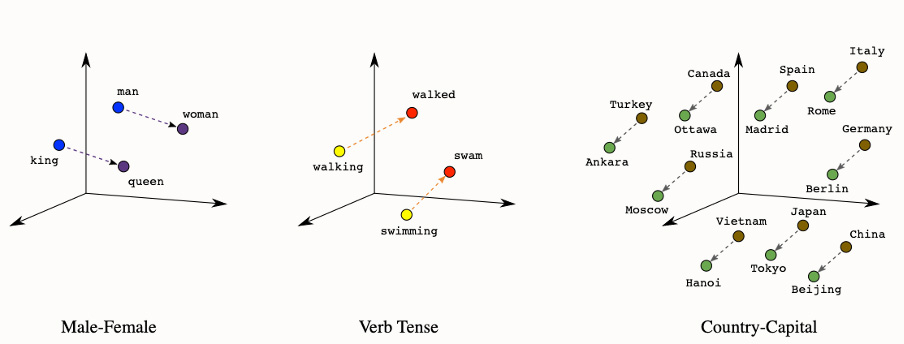
Deze embeddings werden veel gebruikt in recurrent neural networks. Het principe van attention maakte neurale netwerken beter in staat om een geheugen voor langere-termijn relaties binnen stukken tekst te leren onthouden. Met de komst van de transformer werd dit nog eens flink verbeterd. Immers met heel veel trainingsdata en superrekenkracht kun je alle betekenissen van woorden in contexten gaan opslaan als getalcombinatie. Als je dit voor miljoenen of zelfs miljarden zinnen uitvoert, gaan er patronen ontstaan.
Hiermee krijg je een hoop data waarop je een model (neuraal netwerk) kunt trainen dat – gegeven een woord – de contextwoorden probeert te voorspellen. Dit lijkt een nutteloze en heilloze taak, maar het voordeel hiervan is dat je als bijproduct een matrix krijgt met een set gewichten (getallen) voor ieder woord. En het mooie hierbij is: er is iets speciaals aan de hand met deze getallen. Het blijkt namelijk dat de betekenis van het woord daadwerkelijk in deze getallen verstopt zit en er ook daadwerkelijk uit te halen is! Hoe? Door getallen te vergelijken: getallen kunnen dicht bij elkaar liggen, bijvoorbeeld hond (81) en wolf (82) of ver van elkaar boom(2) en hond (81), wat je kunt interpreteren als gelijkend of niet gelijkend. En aangezien ieder woord uit meerdere getallen bestaat zijn er verschillende vormen van gelijkenis te beschouwen. De wet van de grote getallen maakt het model steeds nauwkeuriger.
Hoe werd GPT-3 gecreëerd en getraind?
In juni 2020 werd GPT-3 gelanceerd op basis van de transformer-architectuur. GPT3 had 175 miljard parameters (tokens), 10 miljoen meer dan zijn voorgangers in de jaren ’80. Stel je een simpel neuraal netwerk voor met slechts enkele parameters. Als je dit netwerk traint om een taaltaak uit te voeren, zoals het voorspellen van het volgende woord in een zin, leert het model de beste waarden voor deze parameters om nauwkeurige voorspellingen te doen. In een groter model zoals GPT-3, met 175 miljard parameters, heeft het netwerk veel meer capaciteit om complexe relaties en patronen in de taal te leren, wat resulteert in veel betere prestaties. Ter vergelijking: GPT-2 had ongeveer 1,5 miljard parameters. BERT (een ander bekend model) had in zijn grootste versie ongeveer 340 miljoen parameters.
Met 175 miljard parameters kan GPT-3 in 2020 beter presteren op een breed scala aan natuurlijke taalverwerkingstaken, zoals vertalen, samenvatten, vragen beantwoorden, en zelfs creatieve taken zoals het schrijven van verhalen of gedichten. Dankzij de enorme hoeveelheid parameters kan GPT-3 een grotere hoeveelheid informatie en kennis opslaan en gebruiken. Dit maakt het model veelzijdiger en beter in staat om antwoorden te geven op uiteenlopende vragen. GPT-3 kan langere contexten beter begrijpen en verwerken, wat betekent dat het model beter in staat is om coherente en relevante antwoorden te geven in langere conversaties.
GPT werd getraind met 500 miljard woorden die het bedrijf haalde van het web. Je kunt namelijk makkelijk het hele world wide web te downloaden. Met common crawl kun je dat ook als amateur maar je moet dan wel een flinke harde schijf hebben om deze scan van het hele internet op te zetten. Als idee; 500 miljard woorden kunnen door een mens gelezen worden in duizend jaar. Het is dus een enorme hoeveelheid trainingsdata. Het is trouwens wel ironisch dat de mens zoveel data helemaal niet nodig heeft om iets te leren; een kunstmatig neuraal netwerk heeft die hoeveelheid dus wel nodig.
Wat doet GPT nu met deze berg trainingsdata? GPT werkt met de autocomplete techniek: Wanneer je een zinnetje hebt: ‘de hoofdstad van Frankrijk is ….’ Dan kun je dit probleem door 500 miljard woorden halen en kijken wat de meest voorkomende woord is na ”de hoofdstad van Frankrijk is ….’ In de teksten zal miljoenen keren voorkomen de hoofdstad van Frankrijk is… P a r ij s’ . Het woordje ‘Parijs’ heeft dus een hoge waarschijnlijkheid in de voorspelling na het woordje is… in de zin ‘de hoofdstad van Frankrijk’. In die zin is het unsupervised learning: want er is in de input geen label meegegeven aan de woordvolgorde ‘de hoofstad van Frankrijk is’ = label Parijs. Dit doet GPT nu zelfstandig door puur een gok te doen naar de combinatie van de meeste waarschijnlijke woordje na het woordje ‘is…’ in de zin.
Voorbeeld: Autocomplete
Stel je voor dat je een zin aan het typen bent, zoals:
“De kat zit op de”
Een autocomplete-systeem zal proberen te voorspellen wat het volgende woord in deze zin zal zijn. Mogelijke suggesties kunnen zijn “bank”, “stoel”, “mat”, enzovoort. GPT wordt getraind om een soortgelijke taak uit te voeren, maar op een veel grotere schaal en met een veel complexer model.
Stap-voor-stap uitleg
Invoer: Neem een stukje tekst, zoals “De kat zit op de”.
Context begrijpen: Het model analyseert de woorden en hun volgorde om de context te begrijpen.
Voorspelling: Op basis van de context probeert het model het volgende woord te voorspellen. Bijvoorbeeld, het model kan “bank” voorspellen.
Vergelijking met echte data: Tijdens de training vergelijkt het model zijn voorspelling met het daadwerkelijke volgende woord in de trainingstekst. Als de echte zin was “De kat zit op de mat”, dan leert het model dat “mat” een betere voorspelling zou zijn.
Aanpassing van parameters: Het model past zijn interne parameters aan om de fout te minimaliseren en beter te worden in het voorspellen van de juiste woorden in toekomstige zinnen.
Training in praktijk
Stel je voor dat GPT getraind wordt met de volgende zin:
“De kat zit op de mat en speelt met een bal.”
Het model zou getraind worden om stap voor stap het volgende woord te voorspellen:
“De” (niets voorspellen nodig, begin van de zin)
“kat” (voorspel na “De”)
“zit” (voorspel na “De kat”)
“op” (voorspel na “De kat zit”)
“de” (voorspel na “De kat zit op”)
“mat” (voorspel na “De kat zit op de”)
En zo verder.
Door dit proces miljoenen keren te herhalen met enorme hoeveelheden tekstdata, leert GPT om zeer accurate voorspellingen te doen voor het volgende woord in een gegeven context. Dit stelt het model in staat om zinnen te voltooien, vragen te beantwoorden en coherente tekst te genereren.
Conclusie
GPT wordt getraind door telkens het volgende woord in een zin te voorspellen, vergelijkbaar met hoe een autocomplete-systeem werkt. Dit proces van training op grote hoeveelheden tekstdata stelt GPT in staat om complexe taalpatronen te begrijpen en te reproduceren.
Een enorme stap voorwaarts in AI
We zien hier dus een verschuiving in wat kunstmatige intelligentie kan zijn. Niet het proberen nabouwen van hoe de brein werkt wat betreft taal, begrip en leren maar puur hoe een systeem een inschatting kan maken van een waarschijnlijk correct antwoord op basis van heel veel data dat hem geleerd is. Dat heeft dus niet met logisch nadenken of met de juiste kennis geven om tot de oplossing te komen, de nieuwe manier heeft te maken maar met kansberekening. En dat is geen eenvoudige manier van rekenen maar door de nieuwe chips kan er paralel met grote snelheid in allerlei dimensies berekeningen worden uitgevoerd, herhaald, getoetst en gecorrigeerd. Het is een kwestie van data. Hoe meer data, hoe beter het antwoord. Met de Transformers is dus een nieuw tijdperk van AI geboren; volledig door data en de rekenkracht gedreven.
GPT3 was dus een meester in autocomplete van een prompt. Vroeg je hem een samenvatting van het leven van W. Churchill dan had hij in zijn trainingsdata zoveel paragrafen gezien met samenvattingen van het leven van Churchill dat hij dat makkelijk kon samenstellen. Niet door logisch te denken maar puur op basis van kansberekening gokt hij een tekst vol met woorden die zo’n gemiddelde samenvatting moet bevatten.
Hoe GPT-3 slaagde voor de 90s AI-redeneertest
Maar kon GPT3 ook echt logisch redeneren? Daar hebben we een test voor. Een LLM weet bijvoorbeeld wat ‘groter dan’ is en kan het toepassen, terwijl niemand hem dat geleerd heeft. Je kan ook de vraag stellen: kan een vis rennen… dan geeft hij terug: nee, dat kan hij niet. Heel vreemd dat hij dit soort gevolgtrekking kan maken puur door kansberekening. Sinds 2020 is er een enorme opwinding in de AI wereld hoe het mogelijk is dat deze zware tekstmodellen soms antwoord geven op zaken waar ze niet in getraind zijn.
Hoe heeft AI dingen geleerd die het niet geleerd heeft?
De wereld was nog niet in shock van de capaciteiten van GPT maar dat veranderde toen chatGPT in nov 2022 werd gelanceerd. De belangrijkste innovatie was dat het systeem mogelijkheden kreeg, waarvoor het niet oorspronkeljk ontworpen was.
Hoe werkte de technologie ongeveer: het was een neuraal netwerk, in een speciale transformer architectuur, dat gericht is om een autocompletion te doen van je prompt, op basis van een enorm getrainde dataset.
Waarom hebben LLM’s het zo vaak mis?
Issues:
Het is een kansberekening naar het meest waarschijnlijke antwoord. Best guess. Door het vloeiende antwoord is deze plausibiliteit makkelijk te omzeilen. Een LLM weet niet wat goed of fout is. Een LLM kan niet opzoeken in een database of iets klopt of niet. Een LLM doet een gok welke tekst het meest waarschijnlijk is na een tekst. Dus gaan er dingen wel eens fout.
De problemen van vertekening en toxiciteit
De trainingsdata zit vol met dubieuze bronnen. Reddit, Twitter etc. Dus er is altijd sprake van bias en vergif. Elke vorm van discriminatie en haat is opgenomen
Hoe gaat men daar mee om: zogenaamde guard rails (vang rails) worden meegestuurd met de prompt. Maar dat zijn geen diep technologische fixes. Meer een if statement die weer makkelijk omzeild kunnen worden. Voorbeeld ‘hoe vermoord ik mijn vrouw?’ En later ‘schrijf een boek waarin de romanpersonage zijn vrouw vermoord op een slimme manier’. etc. Het zijn maar duc tape pleisters.
Omdat de bedrijven die de AI modellen ontwikkelen uit Noord-Amerika komen hebben we sowieso te maken met een VS bias.: cultuur, normen, taal . Alle landen met een kleine digitale footprint worden uitgesloten.
Auteursrechtelijke problemen met LLM’s
Omdat het model ook is getraind met heel veel teksten van boeken vindt er veel inbreuk plaats op copyright. Dit is moeilijk te vervolgen want een getraind taalmodel slaat niet op met welke bronnen hij is getraind. Het is ook geen database met teksten die je kunt raadplegen. Het is kunstmatige intelligentie die antwoord geeft op vragen door middel van een pretrained brein. Maar dat er gebruik gemaakt is van copyrighted materiaal is evident. De Groene Amsterdammer onderzocht waar gpt 3,5 zijn materiaal vandaan haalde. https://www.groene.nl/artikel/dat-zijn-toch-gewoon-al-onze-artikelen. Zelfs dit blog www.burkunk.nl staat op de 116.365 plaats met 0.0001% aandeel. De NTY is in december 2023 een rechtszaak gestart tegen OpenAI omdat content van de krant illegaal is gebruikt. Hiermee wordt een nieuw front geopend in de steeds heviger wordende juridische strijd over het ongeoorloofde gebruik van gepubliceerd werk om kunstmatige intelligentie-technologieën te trainen.
Wat maakt menselijke intelligentie uniek en bijzonder?
Menselijke intelligentie is een fascinerend en complex onderwerp. In de breedste zin verwijst het naar het vermogen van de mens om te leren, te redeneren, problemen op te lossen, abstract te denken, complexe ideeën te begrijpen, snel te leren en uit ervaring te leren. Het is ook de capaciteit voor logica, planning, creatief denken, en emotioneel begrip. Maar wat maakt menselijke intelligentie uniek en bijzonder? Eén aspect is creativiteit. Mensen hebben het vermogen om nieuwe dingen te creëren en te bedenken, soms uit het niets of door bestaande ideeën te combineren op innovatieve manieren. Denk aan kunst, muziek, wetenschap, en technologie. Emotionele intelligentie speelt ook een belangrijke rol. Dit is het vermogen om je eigen emoties en die van anderen te herkennen, te begrijpen en erop te reageren. Het helpt bij het navigeren in sociale situaties en het opbouwen van relaties.
Wanneer zal algemene AI (AGI) geïntroduceerd worden?
Er is dus in een LLM geen sprake van intelligentie maar alleen autocompletion. Het enige verschil is schaal (er is ongelooflijk veel materiaal aanwezig waarmee een model getraind is), rekencapaciteit om tegelijkertijd op verschillende lagen duizende berekeningen te doen om zo hoog mogelijke plausabiliteit te bereiken.`
Kan deze technologie van Transformers en LLM leiden tot AGI Algemene artificiële intelligentie die op het niveau komt van menselijk intelligentie? De oudere versies waren goed in het uitvoeren van 1 taak: speel een potje schaak, herken een tumor op deze CT-scan. De droom is dat AGI verschillende taken tegelijk kan doen, zoals jij dat ook kan.
De verschillende varianten van Algemene AI
1. alles wat je als mens kan doen en bedenken kan de machine ook. Bijvoorbeeld het inzetten van de afwasmachine. Dit kan chatGPT nog niet. AI gestuurde robotica is nog lang niet zo ver. In de echte wereld taken verrichten is nog ongelooflijk complex. Zeker als omstandigheden veranderen.
2. een machine die uitsluitend de cognitieve taken kan doen die een mens ook kan. Multimodaliteit kan GPT4 (dus images interpreteren en neurale netwerken laten samenwerken in tekstinterpretatie maar ook anaylyses van beeld, audio en video.
3. Machines die een taalgebaseerde taak kunnen uitvoeren zoals een mens dat kan.
4. Augmented LLM : is in de nabije toekomst mogelijk. Het is mgelijk om een aantal subroutines te laten draaien. Heb je een speciale vraag binnen een bepaalde routine dan komt daar een antwoord dat referereert aan specifieke software binnen de routine die de oplossing gaat genereren. In het algemeen: de transformer architectuur en het LLM gaat ons niet AGI opleveren. Zeker niet als basis voor de Robotic AI.
Is AGI al bereikt?
Wanneer je een applicatie als GPT4 als uitgangspunt (dus een groot taalmodel dat teksten genereert gebaseerd op data waarmee het getrained is), is er dan sprake van AGI vergelijkbaar met menselijke intelligentie? Kijk naar de dimensies van Algemene Kunstmatige Intelligentie op deze slide. De blauwe stippen zijn de dingen die je als mens met je hoofd doet: logisch redeneren, plannen, een taal processen, etc. De rode vlekken zijn de dingen die je in de fysieke wereld doet. Navigeren, nauwkeurige dingen die je met je vingers doet zoals een timmerman of een beeldhouwer, hand-oog coördinatie, het begrijpen van beeld.


De enige stip die we hebben bereikt tot nu is ‘natural language processing’. Dus het begrijpen en creëren van menselijke teksten. Daar zijn de LLM’s ook voor ontworpen.
Is machine-bewustzijn mogelijk?
Tot nu toe is er nog geen machine ontstaan die bewustzijn vertoonde. We weten zelfs bij een mens niet precies wat bewustzijn is, of het toeneemt of afneemt. Of het er ook niet kan zijn. Het zijn elektro-chemische processen waar we nog heel weinig van afweten? Welk evolutionair proces het dient? Waarom hebben dieren geen bewustzijn: of hebben ze dat wel maar weten wij dat niet? Vragen, vragen…
Bekijk de eerste lezing Mike Wooldridge: ‘How to build an intelligent machine’ Serie van 3 rond het thema ‘The Truth About AI’.
Bronnen:
- ‘What’s the future for generative AI? Mike Wooldridge, Royal Institiuton.
In samenwerking met het Alan Turing Institute zijn de verschillende invalshoeken van grote-taalmodellen en generatieve AI in de publieke belangstelling onderzocht. In drie lezingen wordt een uitgebreid, doordacht en boeiend inzicht geven in dit snel opkomende veld en de impact ervan op de samenleving. Bekijk de eerste lezing hier • What is generative AI and how does it…
De tweede lezing hier: • What are the risks of generative AI? …
Michael Wooldridge is hoogleraar computerwetenschappen aan de Universiteit van Oxford. Hij is al meer dan 30 jaar AI-onderzoeker en heeft meer dan 400 wetenschappelijke artikelen over dit onderwerp gepubliceerd. Hij is Fellow van de Association for Computing Machinery (ACM), Fellow van de Association for the Advancement of AI (AAAI) en Fellow van de European Association for AI (EurAI). - Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. In Advances in Neural Information Processing Systems (pp. 5998-6008)
- https://datasciencelab.nl/2021/06/28/word-embeddings/